

AC40 Support
Welcome to the product training for AC40 audiometer. On this page you will find an overview of all the available training materials and support.
Available Training
Speech Audiometry
What is speech audiometry?
Speech audiometry, also known as speech testing, employs speech signals to assess if the patient has problems hearing speech or speech in noise. Speech audiometry can be used to examine the processing ability and if it is affected by disorders of the middle ear, cochlea, auditory nerve, brainstem pathway, or auditory centers of the cortex.
There is a variety of tests available with speech testing with the basic speech audiometry being an assessment of the reception, discrimination and recognition of speech. Reception refers to the level at which the patient can hear speech is present, discrimination refers to the level at which the patient can discriminate between words, while recognition refers to the level at which the patient can recognize and recall the word.

More advanced speech testing takes into account how speech is understood in the presence of noise, with various noise types such as white noise, speech noise, babble noise, or running speech as noise source and provide information about the signal-to-noise ratio (SNR) at which the patient can understand speech. Other components such as the placement of the speech signal in relation to the noise source and the tonal differences between the speech signal and the masking signal, is some of the things incorporated into more advance speech testing.
Speech detection threshold (SDT)
The speech detection threshold (SDT) is the level at which speech is audible to a person in 50% of the cases. It serves as a valuable cross-check for air conduction audiometry, and should closely align with the pure tone average (PTA). The PTA is typically calculated by averaging the thresholds obtained at 500, 1000, and 2000 Hz. A difference between the PTA and SDT of ±6 dB is good, ±7 to 12 dB is adequate, while ±13 dB or more is poor.
Note: Speech detection threshold is sometimes referred to as speech reception threshold abbreviated - SRT, not to be confused with speech recognition threshold, abbreviated - SRT. For that matter the term speech detection threshold is used and abbreviated – SDT.
Speech recognition threshold (SRT)
The speech recognition threshold (SRT) is the minimum hearing level at which an individual can correctly repeat 50% of the speech material, typically involving numbers or spondaic words. This measure serves as an indicator of hearing sensitivity for speech and provides a baseline for other assessments like Word Recognition (WR) tests, enabling the determination of appropriate starting points for further evaluations.
Word recognition score (WR)
The word recognition score (WR) is sometimes also referred to as SDS (speech discrimination score) and represents the number of words correctly repeated, expressed as a percentage of correct (discrimination score) or incorrect (discrimination loss). Pressing correct means the word is a 100% correct, while incorrect correspond with 0% correct.
The score can be obtained as a phoneme score that provides information about what phonemes the patient has difficulty hearing at a particular intensity level. This is helpful for counselling and rehabilitation purposes.
Discrimination score / discrimination loss
In the suite. Correct: A mouse click on this button will store the word as correctly repeated. The left arrow key can also be used for storing as correct. Incorrect: A mouse click on this button will store the word as incorrectly repeated. The right arrow key can also be used to score as incorrect. Store: A mouse click on this button will store the speech threshold in the speech graph. A point can also be stored by pressing S.

On the standalone devices. Press incorrect on the keyboard to store the word as incorrect (0%) or press correct on the keyboard to store the word as correct (100%).
Phoneme score
When the speech material is indexed according to the number of phonemes in each word, the soft key numbers available for scoring will be active.

E.g. for a word with two phonemes the soft keys 0,1 and 2 will become available for scoring. The upper the display in the suites, while the lower displays the buttons on the standalone audiometer.

When the word is scored with the use of phonemes, the number of correct phonemes will appear below the word.
![]()
The percentage will be calculated as the numbers of phonemes correct out of the total number of phonemes that has been presented up until the given word.
![]()
Thereby the storing can be done at any time during the scoring.
Required equipment
- Headphones, insert phones, or free field speakers
- A microphone, external sound player, or built-in wave files
- Talk back microphone and talk forward microphone
Speech audiometry test procedure
Before performing speech audiometry you may wish to do the tone audiogram. This provides valuable predictive information useful in the speech testing, including information about when masking is needed during speech testing. For more information about masking please refer to the quick guide ‘Audiometric masking’.
- Press the Tests button and select the speech test.
- If needed, select the measurement type (e.g. WR1, WR2, SRT), type of measure (word, numbers, multi syllabic numbers and multi syllabic words), and list of words using the soft buttons.
- Select the intensity levels for channel If masking is needed configure channel 2 also.
- Explain to the patient that he/she will now hear some words/numbers/sentences though the ear phones/free field speakers. Instruct the patient to repeat what is said even though it may be very Patients may also be encouraged to guess if they are unsure about the word/number/sentence. If performing the speech test in noise do not forget to instruct the patient not to focus on the noise but on the speech.
- Press Start to start presenting the words, numbers or sentences.
- Based on the settings for speech, the response can be scored as Correct, Incorrect using the hardkeys or numbers of correct phonemes using the softkeys
 .
. - Click on Store to store the results.
Speech audiometry results
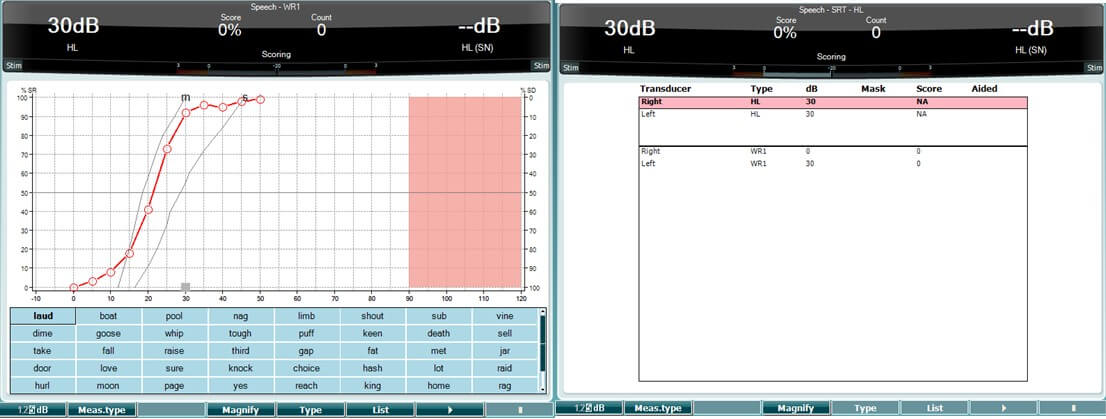
1. Table mode
The SRT/WR displayed as a table allows for measuring multiple SRTs using different test parameters, e.g. Transducer, Test Type, Intensity, Masking, and Aided together with the SRT or WR score.
2. Graph mode
When showing the SRT in graph mode the speech audiogram calculates the SRT value based on the norm curve (the distance in dB from the point where the norm curve crosses 50% to the point where the speech curve crosses 50%) like shown below. The result is then an expression of how much you need to turn up the level compared to normal in order for the patient to be able to repeat 50%.
Use the m-curve for multi syllabic words and the s-curve if using single syllabic words. The curves can be edited according to the normative data you wish to use in the speech settings.
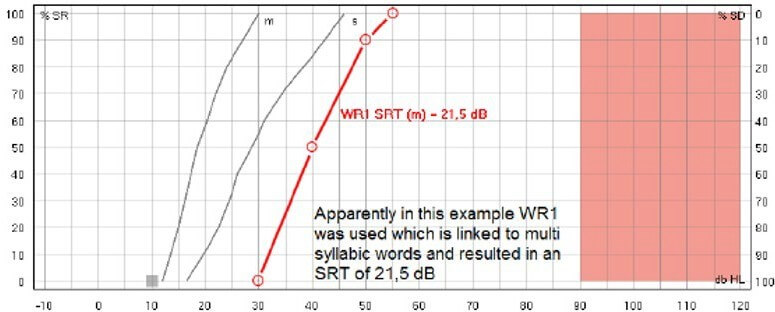
Note that the norm curves change based on the speech material. You must therefore ensure that WR1, WR2 or WR3 is linked to single or multisyllabic words to show the SRT. Calculating the WR SRT is only available when using the suite.
Speech setup
When running the speech test using wavefiles, the tester can decide to present manually, continuously or timeout for the speech setup.
Manual mode allows the tester to manually press the Tone Switch/Enter button to present the word and then score it as Incorrect of Correct before moving on to the next word.
In Continuous mode, the next word will automatically be presented after scoring incorrect or correct.
In the Time Out mode, the word played will be scored as either correct or incorrect if no scoring is entered within 1 to 5 seconds.
Speech in noise
Problems understanding speech in noise is a common complaint from people with hearing loss. Having the ability to test the patient with speech in noise provides useful information about the impact of the hearing loss on the patient’s ability to communicate. It also provides information about whether the patient is actually getting the expected benefit from the hearing aids when communicating in noisy environments.
Testing the patient in a speech in noise setup can be done using a free field setup either by presenting the speech signal and noise signal from the same speaker or alternatively, separating the speech signal and noise signal by presenting the signal from two different speakers. It can be done by presenting the signal and noise to the same ear on the AC40 or by selecting the test speech in noise on the AD629.
Binaural speech
If the intention is to present the speech signal to both ears at the same time this is done by selecting the same output for both channels on the AC40. On the AD629 the binaural speech is selected by choosing the test Speech - Ch2on. Note this is only available with the AD629 extended.
References
Stach, B.A (1998) Clinical Audiology: An introduction, Cengage Learning