
Speech Audiometry: An Introduction
Description
Table of contents
- What is speech audiometry?
- Why perform speech audiometry?
- Contraindications and considerations
- Audiometers that can perform speech audiometry
- How to perform speech audiometry?
- Results interpretation
- Calibration for speech audiometry
What is speech audiometry?
Speech audiometry is an umbrella term used to describe a collection of audiometric tests using speech as the stimulus. You can perform speech audiometry by presenting speech to the subject in both quiet and in the presence of noise (e.g. speech babble or speech noise). The latter is speech-in-noise testing and is beyond the scope of this article.
Speech audiometry is a core test in the audiologist’s test battery because pure tone audiometry (the primary test of hearing sensitivity) is a limited predictor of a person’s ability to recognize speech. Improving an individual’s access to speech sounds is often the main motivation for fitting them with a hearing aid. Therefore, it is important to understand how a person with hearing loss recognizes or discriminates speech before fitting them with amplification, and speech audiometry provides a method of doing this.
Why perform speech audiometry?
A decrease in hearing sensitivity, as measured by pure tone audiometry, results in greater difficulty understanding speech. However, the literature also shows that two individuals of the same age with similar audiograms can have quite different speech recognition scores. Therefore, by performing speech audiometry, an audiologist can determine how well a person can access speech information.
Acquiring this information is key in the diagnostic process. For instance, it can assist in differentiating between different types of hearing loss. You can also use information from speech audiometry in the (re)habilitation process. For example, the results can guide you toward the appropriate amplification technology, such as directional microphones or remote microphone devices. Speech audiometry can also provide the audiologist with a prediction of how well a subject will hear with their new hearing aids. You can use this information to set realistic expectations and help with other aspects of the counseling process.
Below are some more examples of how you can use the results obtained from speech testing.
Identify need for further testing
Based on the results from speech recognition testing, it may be appropriate to perform further testing to get more information on the nature of the hearing loss. An example could be to perform a TEN test to detect a dead region or to perform the Audible Contrast Threshold (ACT™) test.
Inform amplification decisions
You can use the results from speech audiometry to determine whether binaural amplification is the most appropriate fitting approach or if you should consider alternatives such as CROS aids.
Counseling
You can use the results obtained through speech audiometry to discuss and manage the amplification expectations of patients and their communication partners.
Referral
Unexpected asymmetric speech discrimination, significant roll-over, or particularly poor speech discrimination may warrant further investigation by a medical professional.
Non-organic hearing loss
You can use speech testing to cross-check the results from pure tone audiometry for suspected non‑organic hearing loss.
Contraindications and considerations when performing speech audiometry
Before speech audiometry, it is important that you perform pure tone audiometry and otoscopy. Results from these procedures can reveal contraindications to performing speech audiometry.
Otoscopic findings
Speech testing using headphones or inserts is generally contraindicated when the ear canal is occluded with:
- Wax
- Debris
- Foreign body
- Or infective otitis externa
In these situations, you can perform bone conduction speech testing or sound field testing.
Audiometric findings
Speech audiometry can be challenging to perform in subjects with severe-to-profound hearing losses as well as asymmetrical hearing losses where the level of stimulation and/or masking noise required is beyond the limits of the audiometer or the patient's uncomfortable loudness levels (ULLs).
Subject variables
Depending on the age or language ability of the subject, complex words may not be suitable. This is particularly true for young children and adults with learning disabilities or other complex presentations such as dementia and reduced cognitive function.
You should also perform speech audiometry in a language which is native to your patient. Speech recognition testing may not be suitable for patients with expressive speech difficulties. However, in these situations, speech detection testing should be possible.
Audiometers that can perform speech audiometry
Before we discuss speech audiometry in more detail, let’s briefly consider the instrumentation to deliver the speech stimuli. As speech audiometry plays a significant role in diagnostic audiometry, many audiometers include – or have the option to include – speech testing capabilities.
Table 1 outlines which audiometers from Interacoustics can perform speech audiometry.
| Audiometer | Type |
| AC40 | Clinical audiometer |
| AD528 | Diagnostic audiometer |
| AD629 | Diagnostic audiometer |
| Affinity Compact | Hearing aid fitting system |
| Callisto™ | Portable audiometer |
| Equinox Evo | Clinical audiometer |
Table 1: Audiometers from Interacoustics that can perform speech audiometry.
How to perform speech audiometry?
Because speech audiometry uses speech as the stimulus and languages are different across the globe, the way in which speech audiometry is implemented varies depending on the country where the test is being performed. For the purposes of this article, we will start with addressing how to measure speech in quiet using the international organization of standards ISO 8252-3:2022 as the reference to describe the terminology and processes encompassing speech audiometry. We will describe two tests: speech detection testing and speech recognition testing.
Speech detection testing
In speech detection testing, you ask the subject to identify when they hear speech (not necessarily understand). It is the most basic form of speech testing because understanding is not required. However, it is not commonly performed. In this test, words are normally presented to the ear(s) through headphones (monaural or binaural testing) or through a loudspeaker (binaural testing).
Speech detection threshold (SDT)
Here, the tester will present speech at varying intensity levels and the patient identifies when they can detect speech. The goal is to identify the level at which the patient detects speech in 50% of the trials. This is the speech detection threshold. It is important not to confuse this with the speech discrimination threshold. The speech discrimination threshold looks at a person’s ability to recognize speech and we will explain it later in this article.
The speech detection threshold has been found to correlate well with the pure tone average, which is calculated from pure tone audiometry. Because of this, the main application of speech detection testing in the clinical setting is confirmation of the audiogram.
Speech recognition testing
In speech recognition testing, also known as speech discrimination testing, the subject must not only detect the speech, but also correctly recognize the word or words presented. This is the most popular form of speech testing and provides insights into how a person with hearing loss can discriminate speech in ideal conditions.
Across the globe, the methods of obtaining this information are different and this often leads to confusion about speech recognition testing. Despite there being differences in the way speech recognition testing is performed, there are some core calculations and test parameters which are used globally.
Speech recognition testing: Calculations
There are two main calculations in speech recognition testing.
1. Speech recognition threshold (SRT)
This is the level in dB HL at which the patient recognizes 50% of the test material correctly. This level will differ depending on the test material used. Some references describe the SRT as the speech discrimination threshold or SDT. This can be confusing because the acronym SDT belongs to the speech detection threshold. For this reason, we will not use the term discrimination but instead continue with the term speech recognition threshold.
2. Word recognition score (WRS)
In word recognition testing, you present a list of phonetically balanced words to the subject at a single intensity and ask them to repeat the words they hear. You score if the patient repeats these words correctly or incorrectly. This score, expressed as a percentage of correct words, is calculated by dividing the number of words correctly identified by the total number of words presented.
In some countries, multiple word recognition scores are recorded at various intensities and plotted on a graph. In other countries, a single word recognition score is performed using a level based on the SRT (usually presented 20 to 40 dB louder than the SRT).
Speech recognition testing: Parameters
Before completing a speech recognition test, there are several parameters to consider.
1. Test transducer
You can perform speech recognition testing using air conduction, bone conduction, and speakers in a sound-field setup.
2. Types of words
Speech recognition testing can be performed using a variety of different words or sentences. Some countries use monosyllabic words such as ‘boat’ or ‘cat’ whereas other countries prefer to use spondee words such as ‘baseball’ or ‘cowboy’. These words are then combined with other words to create a phonetically balanced list of words called a word list.
3. Number of words
The number of words in a word list can impact the score. If there are too few words in the list, then there is a risk that not enough data points are acquired to accurately calculate the word recognition score. However, too many words may lead to increased test times and patient fatigue. Word lists often consist of 10 to 25 words.
4. Scoring
You can either score words as whole words or by the number of phonemes they contain.
An example of scoring can be illustrated by the word ‘boat’. When scoring using whole words, anything other than the word ‘boat’ would result in an incorrect score.
However, in phoneme scoring, the word ‘boat’ is broken down into its individual phonemes: /b/, /oa/, and /t/. Each phoneme is then scored as a point, meaning that the word boat has a maximum score of 3. An example could be that a patient mishears the word ‘boat’ and reports the word to be ‘float’. With phoneme scoring, 2 points would be awarded for this answer whereas in word scoring, the word float would be marked as incorrect.
5. Delivery of material
Modern audiometers have the functionality of storing word lists digitally onto the hardware of the device so that you can deliver a calibrated speech signal the same way each time you test a patient. This is different from the older methods of testing using live voice or a CD recording of the speech material. Using digitally stored and calibrated speech material in .wav files provides the most reliable and repeatable results as the delivery of the speech is not influenced by the tester.
6. Aided or unaided
You can perform speech recognition testing either aided or unaided. When performing aided measurements, the stimulus is usually played through a loudspeaker and the test is recorded binaurally.
Global examples of how speech recognition testing is performed and reported
Below are examples of how speech recognition testing is performed in the US and the UK. This will show how speech testing varies across the globe.
Speech recognition testing in the US: Speech tables
In the US, the SRT and WRS are usually performed as two separate tests using different word lists for each test. The results are displayed in tables called speech tables.
SRT
The SRT is the first speech test which is performed and typically uses spondee words (a word with two equally stressed syllables, such as ‘hotdog’) as the stimulus. During this test, you present spondee words to the patient at different intensities and a bracketing technique establishes the threshold at where the patient correctly identifies 50% of the words.
In the below video, we can see how an SRT is performed using spondee words.
Below, you can see a table showing the results from an SRT test (Figure 1). Here, we can see that the SRT has been measured in each ear. The table shows the intensity at which the SRT was found as well as the transducer, word list, and the level at which masking noise was presented (if applicable). Here we see an unaided SRT of 30 dB HL in both the left and right ears.

WRS
Once you have established the intensity of the SRT in dB HL, you can use it to calculate the intensity to present the next list of words to measure the WRS. In WRS testing, it is common to start at an intensity of between 20 dB and 40 dB louder than the speech recognition threshold and to use a different word list from the SRT. The word lists most commonly used in the US for WRS are the NU-6 and CID-W22 word lists.
In word recognition score testing, you present an entire word list to the test subject at a single intensity and score each word based on whether the subject can correctly repeat it or not. The results are reported as a percentage.
The video below demonstrates how to perform the word recognition score.
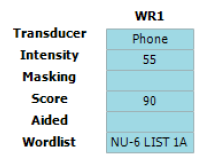
Below is an image of a speech table showing the word recognition score in the left ear using the NU‑6 word list at an intensity of 55 dB HL (Figure 2). Here we can see that the patient in this example scored 90%, indicating good speech recognition at moderate intensities.
Speech recognition testing in the UK: Speech audiogram
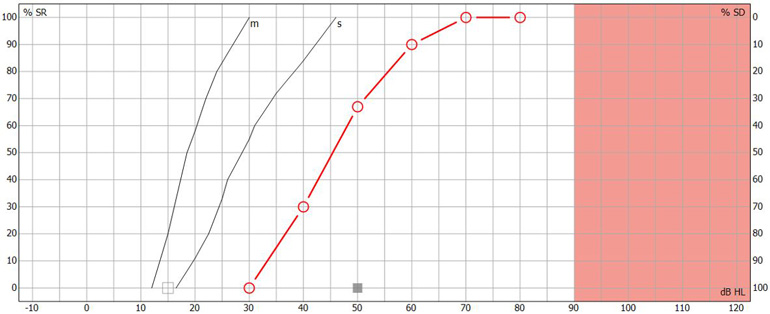
In the UK, speech recognition testing is performed with the goal of obtaining a speech audiogram. A speech audiogram is a graphical representation of how well an individual can discriminate speech across a variety of intensities (Figure 3).
In the UK, the most common method of recording a speech audiogram is to present several different word lists to the subject at varying intensities and calculate multiple word recognition scores. The AB (Arthur Boothroyd) word lists are the most used lists. The initial list is presented around 20 to 30 dB sensation level with subsequent lists performed at quieter intensities before finally increasing the sensation level to determine how well the patient can recognize words at louder intensities.
The speech audiogram is made up of plotting the WRS at each intensity on a graph displaying word recognition score in % as a function of intensity in dB HL. The following video explains how it is performed.
Below is an image of a completed speech audiogram (Figure 4). There are several components.
Point A on the graph shows the intensity in dB HL where the person identified 50% of the speech material correctly. This is the speech recognition threshold or SRT.
Point B on the graph shows the maximum speech recognition score which informs the clinician of the maximum score the subject obtained.
Point C on the graph shows the reference speech recognition curve; this is specific to the test material used (e.g., AB words) and method of presentation (e.g., headphones), and shows a curve which describes the median speech recognition scores at multiple intensities for a group of normal hearing individuals.
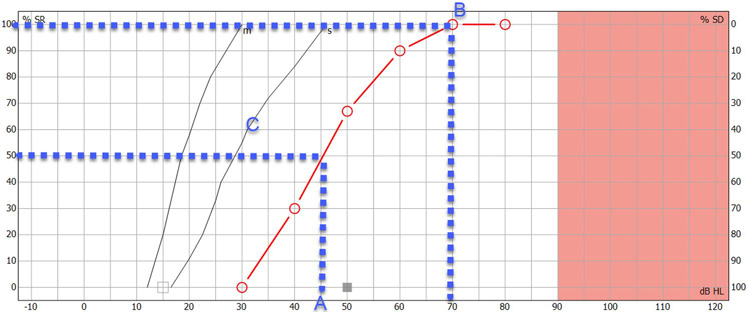
Having this displayed on a single graph can provide a quick and easy way to determine and analyze the ability of the person to hear speech and compare their results to a normative group. Lastly, you can use the speech audiogram to identify roll-over. Roll-over occurs when the speech recognition deteriorates at loud intensities and can be a sign of retro-cochlear hearing loss. We will discuss this further in the interpretation section.
Masking in speech recognition testing
Just like in audiometry, cross hearing can also occur in speech audiometry. Therefore, it is important to mask the non-test ear when testing monaurally. Masking is important because word recognition testing is usually performed at supra-threshold levels. Speech encompasses a wide spectrum of frequencies, so the use of narrowband noise as a masking stimulus is not appropriate, and you need to modify the masking noise for speech audiometry. In speech audiometry, speech noise is typically used to mask the non-test ear.
There are several approaches to calculating required masking noise level. An equation by Coles and Priede (1975) suggests one approach which applies to all types of hearing loss (sensorineural, conductive, and mixed):
- Masking level = DS plus max ABGNT minus 40 plus EM
It considers the following factors.
1. Dial setting
DS is the level of dial setting in dB HL for presentation of speech to the test ear.
2. Air-bone gap
Max ABGNT is the maximum air-bone gap between 250 to 4000 Hz in the non‑test ear.
3. Interaural attenuation
Interaural attenuation: The value of 40 comes from the minimum interaural attenuation for masking in audiometry using headphones (for insert earphones, this would be 55 dB).
4. Effective masking
EM is effective masking. Modern audiometers are calibrated in EM, so you don’t need to include this in the calculation. However, if you are using an old audiometer calibrated to an older calibration standard, then you should calculate the EM.
You can calculate it by measuring the difference in the speech dial setting presented to normal listeners at a level that yields a score of 95% in quiet and the noise dial setting presented to the same ear that yields a score less than 10%.
Results interpretation
You can use the results from speech audiometry for many purposes. The below section describes these applications.
1. Cross-check against pure tone audiometry results
The cross-check principle in audiology states that no auditory test result should be accepted and used in the diagnosis of hearing loss until you confirm or cross-check it by one or more independent measures (Hall J. W., 3rd, 2016). Speech-in-quiet testing serves this purpose for the pure tone audiogram.
The following scores and their descriptions identify how well the speech detection threshold and the pure tone average correlate (Table 2).
| Difference between SDT and PTA | Correlation |
| 6 dB or less | Good |
| 7 to 12 dB | Adequate |
| 13 dB or more | Poor |
Table 2: Correlation between speech detection threshold and pure tone average.
If there is a poor correlation between the speech detection threshold and the pure tone average, it warrants further investigation to determine the underlying cause or to identify if there was a technical error in the recordings of one of the tests.
2. Detect asymmetries between ears
Another core use of speech audiometry in quiet is to determine the symmetry between the two ears and whether it is appropriate to fit binaural amplification. Significant differences between ears can occur when there are two different etiologies causing hearing loss.
An example of this could be a patient with sensorineural hearing loss who then also contracts unilateral Meniere’s disease. In this example, it would be important to understand if there are significant differences in the word recognition scores between the two ears. If there are significant differences, then it may not be appropriate for you to fit binaural amplification, where other forms of amplification such as contralateral routing of sound (CROS) devices may be more appropriate.
3. Identify if further testing is required
The results from speech audiometry in quiet can identify whether further testing is required. This could be highlighted in several ways.
One example could be a severe difference in the SRT and the pure tone average. Another example could be significant asymmetries between the two ears. Lastly, very poor speech recognition scores in quiet might also be a red flag for further testing.
In these examples, the clinician might decide to perform a test to detect the presence of cochlear dead regions such as the TEN test or an ACT test to get more information.
4. Detect retro-cochlear hearing loss
In subjects with retro-cochlear causes of hearing loss, speech recognition can begin to deteriorate as sounds are made louder. This is called ‘roll-over’ and is calculated by the following equation:
- Roll-over index = (maximum score minus minimum score) divided by maximum score
If roll-over is detected at a certain value (the value is dependent on the word list chosen for testing but is commonly larger than 0.4), then it is considered to be a sign of retro-cochlear pathology. This could then have an influence on the fitting strategy for patients exhibiting these results.
It is important to note however that as the cross-check principle states, you should interpret any roll-over with caution and you should perform additional tests such as acoustic reflexes, the reflex decay test, or auditory brainstem response measurements to confirm the presence of a retro-cochlear lesion.
5. Predict success with amplification
The maximum speech recognition score is a useful measure which you can use to predict whether a person will benefit from hearing aids. More recent, and advanced tests such as the ACT test combined with the Acceptable Noise Level (ANL) test offer good alternatives to predicting hearing success with amplification.
Calibration for speech audiometry
Just like in pure tone audiometry, the stimuli which are presented during speech audiometry require annual calibration by a specialized technician ster. Checking of the transducers of the audiometer to determine if the speech stimulus contains any distortions or level abnormalities should also be performed daily. This process replicates the daily checks a clinicians would do for pure tone audiometry. If speech is being presented using a sound field setup, then you can use a sound level meter to check if the material is being presented at the correct level.
The next level of calibration depends on how the speech material is delivered to the audiometer. Speech material can be presented in many ways including live voice, CD, or installed WAV files on the audiometer. Speech being presented as live voice cannot be calibrated but instead requires the clinician to use the VU meter on the audiometer (which indicates the level of the signal being presented) to determine if they are speaking at the correct intensity. Speech material on a CD requires daily checks and is also performed using the VU meter on the audiometer. Here, a speech calibration tone track on the CD is used, and the VU meter is adjusted accordingly to the desired level as determined by the manufacturer of the speech material.
The most reliable way to deliver a speech stimulus is through a WAV file. By presenting through a WAV file, you can skip the daily tone-based calibration as this method allows you to calibrate the speech material as part of the annual calibration process. This saves the clinician time and ensures the stimulus is calibrated to the same standard as the pure tones in their audiometer. To calibrate the WAV file stimulus, the speech material is calibrated against a speech calibration tone. This is stored on the audiometer. Typically, a 1000 Hz speech tone is used for the calibration and the calibration process is the same as for a 1000 Hz pure tone calibration.
Lastly, if the speech is being presented through the sound field, a calibration professional should perform an annual sound field speaker calibration using an external free field microphone aimed directly at the speaker from the position of the patient’s head.
References
Coles, R. R., & Priede, V. M. (1975). Masking of the non-test ear in speech audiometry. The Journal of laryngology and otology, 89(3), 217–226.
Graham, J. Baguley, D. (2009). Ballantyne's Deafness, 7th Edition. Whiley Blackwell.
Hall J. W., 3rd (2016). Crosscheck Principle in Pediatric Audiology Today: A 40-Year Perspective. Journal of audiology & otology, 20(2), 59–67.
Katz, J. (2009). Handbook of Clinical Audiology. Wolters Kluwer.
Killion, M. C., Niquette, P. A., Gudmundsen, G. I., Revit, L. J., & Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners. The Journal of the Acoustical Society of America, 116(4), 2395–2405.
Stach, B.A (1998). Clinical Audiology: An Introduction, Cengage Learning.
Presenter
