
Should You Repeat the ASSR at Threshold?
Description
Question
I read this new article, which is pretty positive about the Eclipse ASSR (Sininger et al 2018). But it raised a question about clinical practice which is not clear to me. Is it necessary to repeat the ASSR at threshold just like in an ABR test?
Answer
The ASSR is such a powerful tool and most valuable to audiologists so this data is key. In the first generation of ASSR we saw many advantages (fully objective, no tester bias, binaural testing and the measurement of multiple stimulus frequencies simultaneously). However, it might be debatable to suggest the true potential of the procedure in terms of test speed wasn’t quite realised. This has probably held us back a little bit as a profession until now with this second generation ASSR system, as illustrated by Sininger et al (2018)
The short answer is no, you do not need to repeat the ASSR to obtain two responses at threshold level as is often done in ABR procedures.
Allow me to break that answer down a little bit and provide a full rationale for you.
When we repeat the ABR to get two traces, what we are doing here is overlaying the two traces to visually assess the reliability of what we think might be the response. To phrase that a bit more accurately, we are trying to determine whether the response is clearly present above the residual noise of the averaged traces.
When we do this visually, it is using a technique sometimes known as the “average gap” method i.e. if the residual noise is sufficiently low in both traces so that the response can be seen then the two traces, when overlaid, will be very similar to one another. The average gap will be low and, if a response is present the waveform should have a morphology consistent with an ABR (wave V) but if it is absent we should see a “flat” trace. If the residual noise is high then the two traces, when overlaid, will not be very similar to one another and the response if present, cannot reliably be differentiated from the residual noise. Have a look at the schematic below, which illustrates this. The top panel shows a small gap between two hypothetical ABRs that are overlaid (low residual noise) and the lower panel shows bigger gaps between the two overlaid traces (high residual noise). The schematics on the left represent the traces as we might see them on an evoked potential system, whereas the schematics on the right show the traces with the gap highlighted in grey.
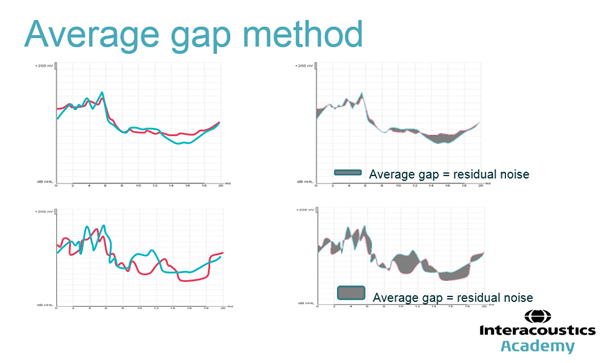
This technique is somewhat outdated. It stems from a time when evoked potentials instruments did not provide an automated (and fully objective) measure of residual noise. It has a number of drawbacks. Firstly, it requires the tester to repeat the whole ABR procedure twice so that two traces are obtained which each have enough epochs to make a sensible comparison. This uses up precious test time. Secondly, the estimation of residual noise is entirely subjective as it relies on the tester to accurately gauge the gap visually, and this is open to tester bias and error. Tester bias and error has been the Achilles heel of the (otherwise objective) ABR procedure for many years, particularly because it relies on the tester making a mental picture of the gap (EP instruments do not highlight the gap in grey like in my diagram above). Another pitfall is that it relies on the tester overlaying the two traces properly. Please note, the Eclipse can automatically superimpose waveforms, but testers are still free to drag and drop the traces and move them on top of each other to wherever they “think” is best. This is a potential source of tester bias as it can lead the tester to read too much into what they are seeing.
Modern EP instruments like the Interacoustics Eclipse bypass these issues by providing an objective indication of residual noise, which is calculated statistically based on the variation of the responses across the epochs rather than on the average gap method. This is an objective means to indicate when predetermined “stop” criteria have been reached. In conjunction with the statistical response detection (Fmp and wave reproducibility [cross-correlation]), it means that we no longer strictly need to repeat traces in ABR like in the past. We merely need to obtain enough epochs in one trace to reach a conclusion (either response present or response absent based on response detection and stop criteria). In fact, it would be better not to have two separate traces and instead invest the time in one longer trace with sufficient sweeps to produce an a more reliable statistical picture.
Please note, one cannot say that repeating the ABR traces is wrong as such, but I do suggest that repeating traces at threshold is no longer necessary when objective means are available. Please note that Sininger et al. (2018) did not specify a need to repeat their ABRs accordingly (see their method sections, page 5).
The key message related to ASSR is that exactly the same logic applies. i.e. this technology also uses objective statistical response detection and residual noise calculation, so one only need perform the test once and merely continue testing long enough for the statistical analysis to reach a firm conclusion (either response present or not) and the residual noise (reaching a specified criterion). It does not seem to add anything to do all of this twice. Sininger et al. specified the residual noise stop criteria as =<15 nV.
References
Sininger, Y.S. et al. (2018). Evaluation of speed and accuracy of next-generation auditory steady state response and auditory brainstem response audiometry in children with normal hearing and hearing loss. Ear and Hearing [Epub ahead of print]doi: 10.1097/AUD.0000000000000580.
Presenter
